

在开发的过程中,为了解决阿里图标更新和维护不便的问题,经过摸索和实践,我们大体可以总结为一下几个步骤:
自动化脚本:写一个自动化脚本来实现图标的下载和更新。利用Puppeteer的能力,自动访问阿里图标下载页面,定位下载链接,并下载新的图标。
Puppeteer是一个流行的Node.js库,在开发者中广泛使用的用于网页爬取和自动化任务的工具。它提供两种操作模式,即headfull和headless。在headfull模式下,Puppeteer控制的Chrome或Chromium浏览器是有界面的,也就是可以看到浏览器运行的情况。在此模式下,可以使用浏览器的开发者工具进行调试。这种模式非常适合在本地进行开发和调试。而在headless模式下,它在后台运行,没有用户界面,这种模式非常适合在服务器上运行,因为没有界面,所以可以节省资源减少页面加载时间并提高性能,后面我们将依赖持续集成工具打包上传,因此我们采用无界面模式。
代码示例:

页面就初始化完毕后,我们就可以利用puppeteer提供的API模拟键盘输入、表单自动提交登录网页、监听数据请求等操作,抓取所需数据。当然,获取数据的方法有很多种:我们采用的是监听数据接口的方式,分别获取图标分类信息以及图标分类列表数据。
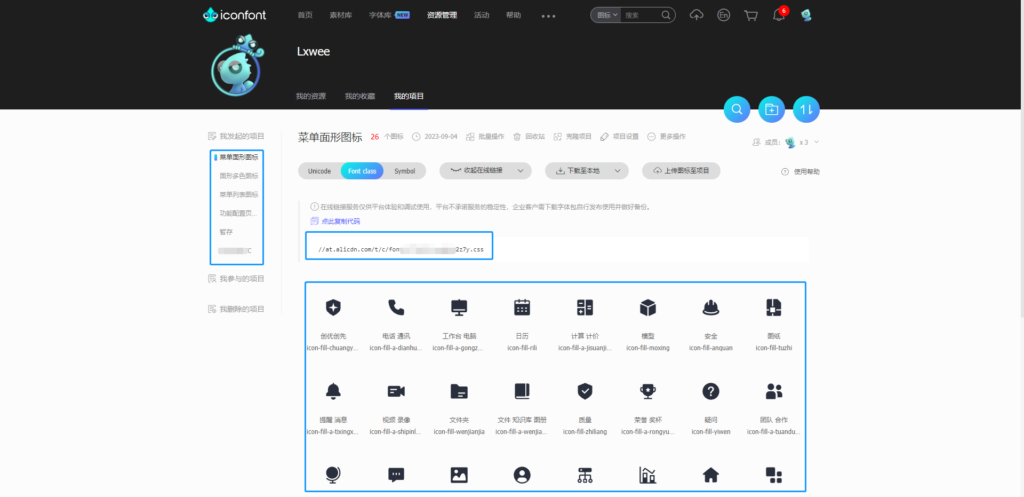
依据这个思路,我们初始化页面完成和登录页面后跳转到我的项目,通过观察页面请求我们很容易得到左侧分类列表数据,右侧图标数据通过左侧分类id请求详情接口获取右侧展示图标数据,包括图标列表、font-family、图标前缀、生成的css文件、生成的js文件等具体信息。
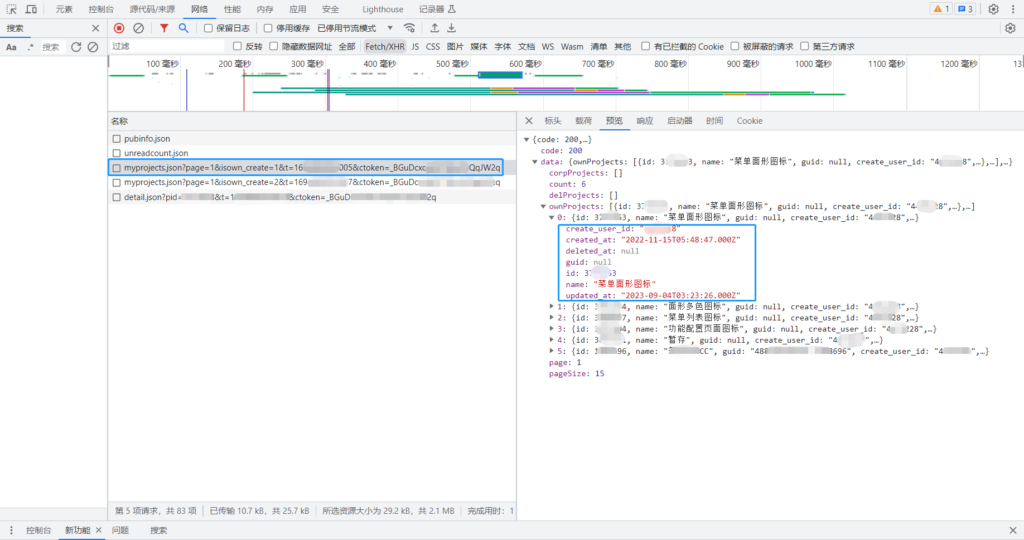

通过监听页面元素的方法判断页面是否加载完毕后,加载完毕后再次调用跳转项目方法,直到左侧分类每一个页面都跳转加载完成并且通过上面的监听取得数据。

需要注意的是,通过puppeteer爬取完数据后必须关闭页面并退出浏览器。
![]()
图标管理:对于下载的图标,建立一个数据库或者使用文件系统来存储和管理这些图标。我们项目中将图标类别和图标列表分别存入数据仓库中。
测试验证:在更新图标后,进行测试以验证图标是否正确显示且符合预期。在验证的过程中,由于获取的图标类较多,而每个分类的图标又由单独的css文件以及js文件构成,因此在测试验证或者正式项目使用的过程中,我们需要在项目初始化之前动态引入多个阿里图标文件。
代码示例:

动态插入阿里图标数据后页面是这样的:

动态插入图标文件
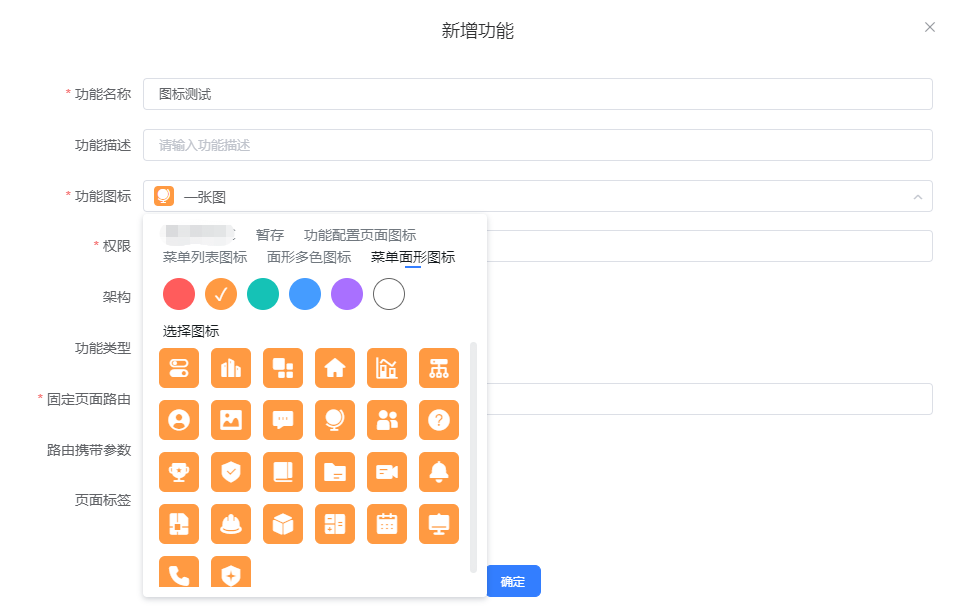
显示效果
持续集成:使用持续集成工具Jenkins,将图标的更新流程集成到目前我们使用的jenkins中,配置自动更新参数,以保证每次代码更新后图标也能自动更新。
总结:阿里图标自动化更新的解决方案最核心的部分就是使用了puppeteer提供的API。 它不仅能操作DOM、缓存资源、支持JavaScript、支持代理,为自动化任务提供了更大的可能性。我们还可以用puppeteer进行UI测试、测试环境,运行测试用例,捕获站点的时间线,追踪和分析网站性能问题,生成PDF和图片,将网页内容转化为静态格式等等。
-1-1024x102.png)


